
AI Driver Assistance

Huawei's robotics research group was developing a physical in-car agent. It was a small anthropomorphic robot mounted on the vehicle dashboard, equipped with cameras and sensors, designed to interact with drivers throughout the entire journey. They had the hardware concept and the deep learning infrastructure, but no coherent model for how the agent should behave. When should it speak? What should it say? How should its tone, posture, and expression change based on what the driver is feeling or what the road looks like? The robotics team needed a behavioural foundation grounded in how humans actually build relationships, read emotion, and respond to social cues. Huawei also wanted the framework to apply to educational contexts, where a similar agent might interact with students during remote learning sessions. Very pandemic-coded.
Driving is emotional, even though it shouldn’t be
The task ahead of us wasn’t really go find how this robot should act, but selecting an emotional model the system would be informed by. I evaluated three families of emotion theory: 2D models (Russell’s circumplex), 3D models (Plutchik’s wheel, Ekman’s basic emotions), and the Cognitive Structure of Emotion (Ortony, Clore, and Collins). The 3D models offered richer expressive range but introduced detection ambiguity that the in-car sensing technology couldn’t reliably utilize. We chose Russell’s valence-arousal model because it provided a reliable perceptual foundation for both humans and machines, with enough granularity to distinguish eight sub-emotional states (happy, astonished, alarmed, frustrated, sad, bored, relaxed, satisfied) within four high-level quadrants.
Next… what should the agent should say? I drew on micro-sociology, specifically Erving Goffman’s social exchange theory, and broke all possible agent interactions into four branches: Exchange (rapport-building small talk), Cooperation (emotional, tangible, informational, and companionship support), Competition (games, challenges, activities), and Conflict (alerts, warnings, errors). Within the Exchange branch, I adapted Demarais and White’s framework of four “social gifts” for building rapport: Appreciation, Connection, Enlightenment, and Elevation. Each of these became a structured response category the system could draw from based on the current context.
I also researched how people form long-term relationships with machines. MIT’s work on Relational AI, which studied how children build social connections with robots, was particularly useful. It introduced the spectrum between transactional interactions (pure utility) and relational interactions (social connection, rapport, shared narrative), and showed that the strongest human-agent bonds developed when the system could move along that spectrum over time. I designed the framework’s relationship class model around how the system tracks interaction direction, frequency, recency, and total relationship length to classify whether the bond is weak-transactional, strong-relational, or somewhere in between, and adapts its response style accordingly. Essentially,
Hello, SARA
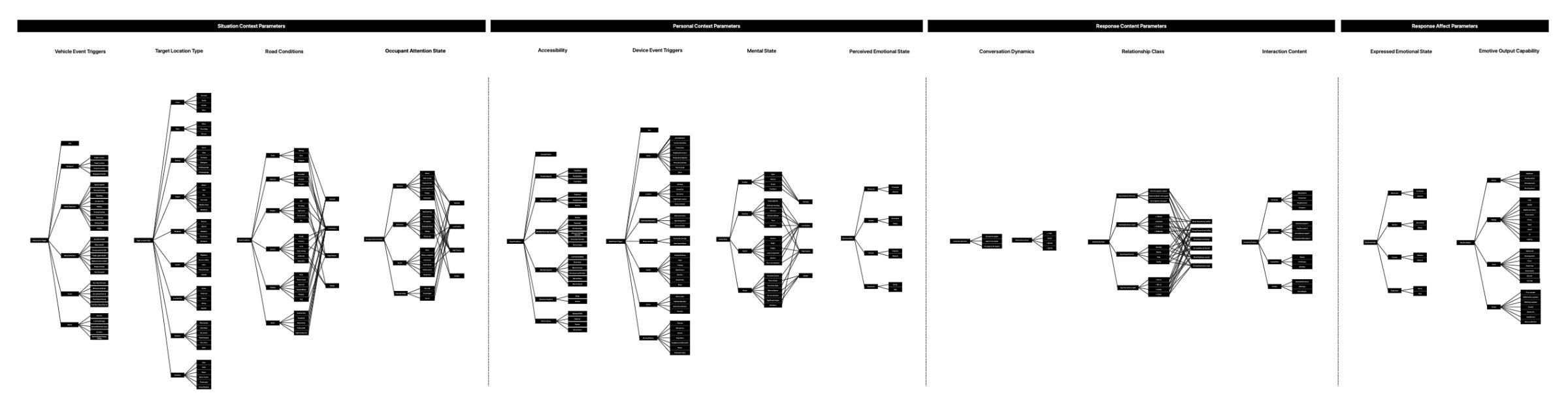
All of this research fed into the core deliverable, a Social Agent Response Architecture (SARA). It’s a four-layer system. The first layer captures situation context (vehicle events, target location, road conditions, occupant attention state). The second captures personal context (accessibility needs, device event triggers, mental state, perceived emotional state). The third determines response content (conversation dynamics, relationship class, interaction type). The fourth filters the response through appropriate emotional affect and maps it to available output channels (motion, display, sound, haptics). Each layer has dozens of enumerated parameters with explicit connections to the layers upstream and downstream.
We built the architecture to work across domains by swapping the situation context layer. For automotive, the parameters cover vehicle operation, road conditions, and distraction states. For education, they cover learning devices, location types, environmental conditions, and attention states. The personal context, response content, and response affect layers remain shared.
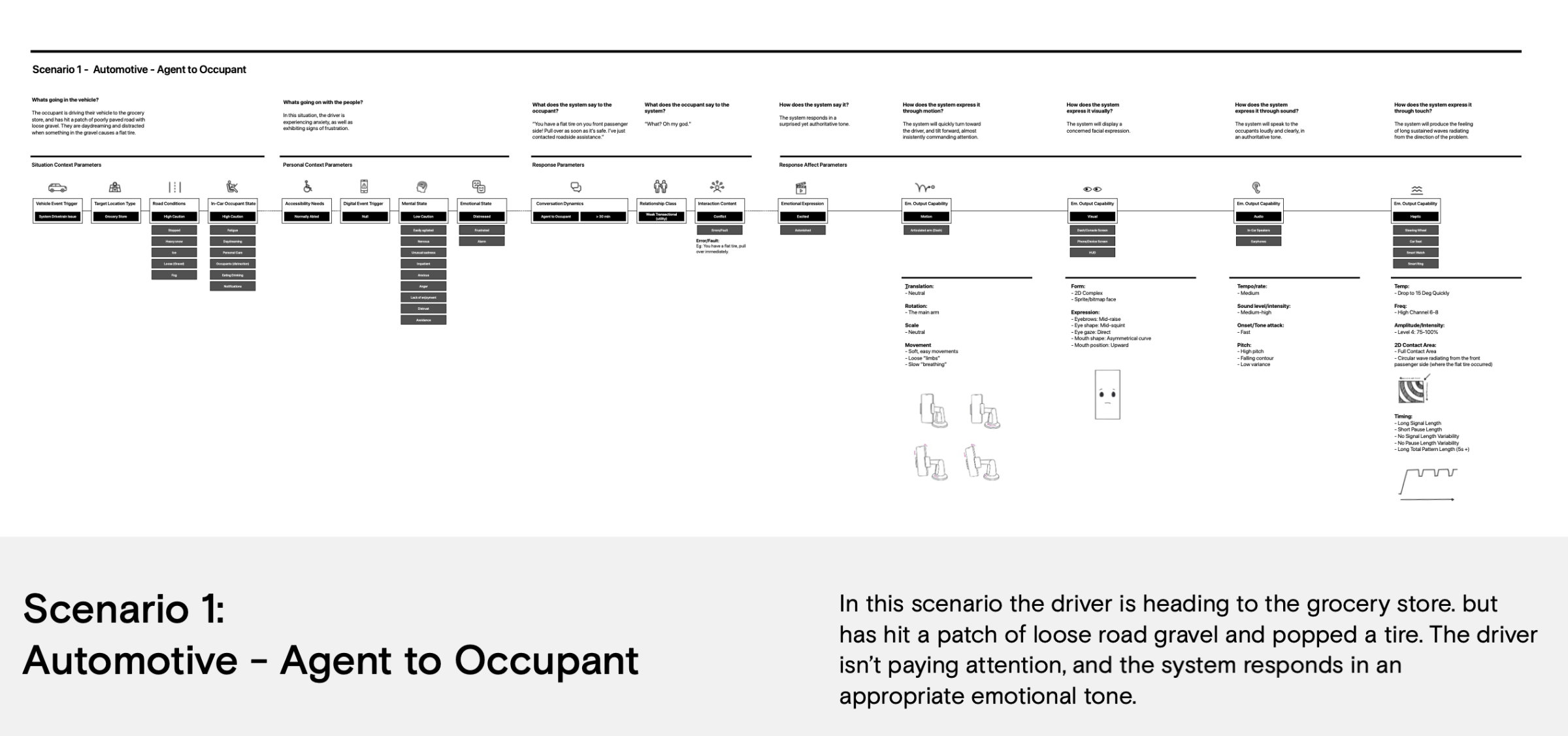
To make the architecture tangible, I designed three detailed scenarios that walk through the full system from trigger to multimodal expression. One scenario covers a safety-critical moment (a flat tire on loose gravel with a distracted driver), where the agent initiates contact in an authoritative, alarmed tone while producing high-frequency steering wheel haptics radiating from the direction of the problem. Another covers a mundane request (a cold driver asks for heat), where the agent responds with warmth and levity because the relationship class is strong-balanced. Each scenario specifies exact parameters for motion (articulated arm translation, rotation, movement quality), visual expression (eyebrow position, eye shape, mouth curve), audio (tempo, intensity, pitch contour), and haptic feedback (frequency channel, amplitude, contact area pattern, timing).
Beyond the response architecture, I produced a complete Emotional Coding Architecture that enumerates the discriminative features for each sensory output channel. For motion, this covers kinematic forms from simple 2D planes through articulated arms to legged robots, with translation, rotation, and scale parameters for each axis. For visual, it covers color, 2D/3D form, facial expression geometry, and posture. For audio, it specifies emotional utterances mapped to 16 affect states plus voice parameters (tempo, intensity, onset, pitch, contour, variability). For haptic, it maps frequency channels, amplitude levels, 2D contact area patterns, temperature range, and timing parameters.

Why did you turn there, driver guy?
We also sketched two additional tools: a crowdsourced “Be the Assistant” game that would let large groups of people seed appropriate responses for different context combinations, and a debugging interface for analysts to inspect, create, and test agent response chains against specific parameter sets. I also did some articulating robotic arm exploration to understand what could provide the most expressive robotic forms for in-car assistance.
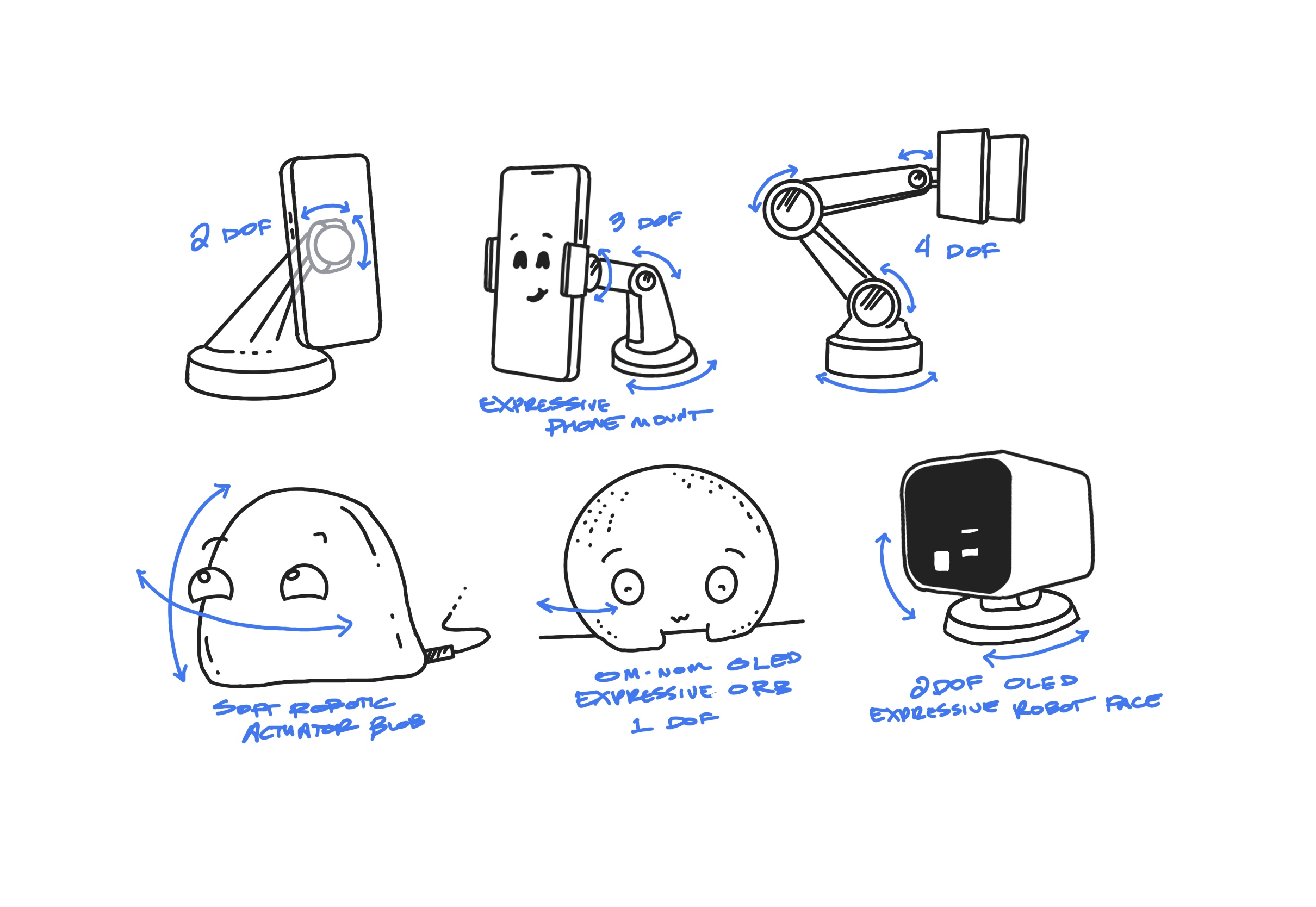
Some of the robotics sketches that influenced HAMOMO
The destination
Huawei filed a design patent (CN306450952S) five months after we delivered the framework. The patent describes an anthropomorphic intelligent robot placed above the centre console, built with a camera and sensors, designed to interact with the driver from door-open to departure. The physical form and behavioural model map directly to the architecture’s specifications for articulated-arm agents with multimodal emotive output.

Meet your fuzzy, expressive AI companion HAMOMO
The framework covered two application domains (automotive and education) and enumerated over 100 contextual parameters across four architectural layers, with emotional expression specified across four sensory channels. The response architecture was designed to scale: with hundreds of parameters and combinatorial context states, it could generate appropriate affective responses for potentially billions of unique situations, a problem the framework addressed through its structured choice architecture rather than brute-force authoring.
The work was completed pre-LLM, using deep learning neural networks as the intended inference backbone. The architectural decisions I made, particularly the choice of Russell’s 2D model for reliable detection, the social exchange theory structure for response selection, and the relational-vs-transactional spectrum for personality adaptation, are the same classes of design problems that AI agent designers face today with large language models. The difference is the surface area… in 2020 we were designing for a physical robot on a dashboard. The pattern applies just as directly to conversational agents, digital assistants, and multimodal AI experiences embedded in software products.